Stairway to Success:Zero-Shot Floor-Aware Object-Goal Navigation via LLM-Driven Coarse-to-Fine Exploration
Stairway to Success:Zero-Shot Floor-Aware Object-Goal Navigation via LLM-Driven Coarse-to-Fine Exploration
Testing our method in real-world environments.
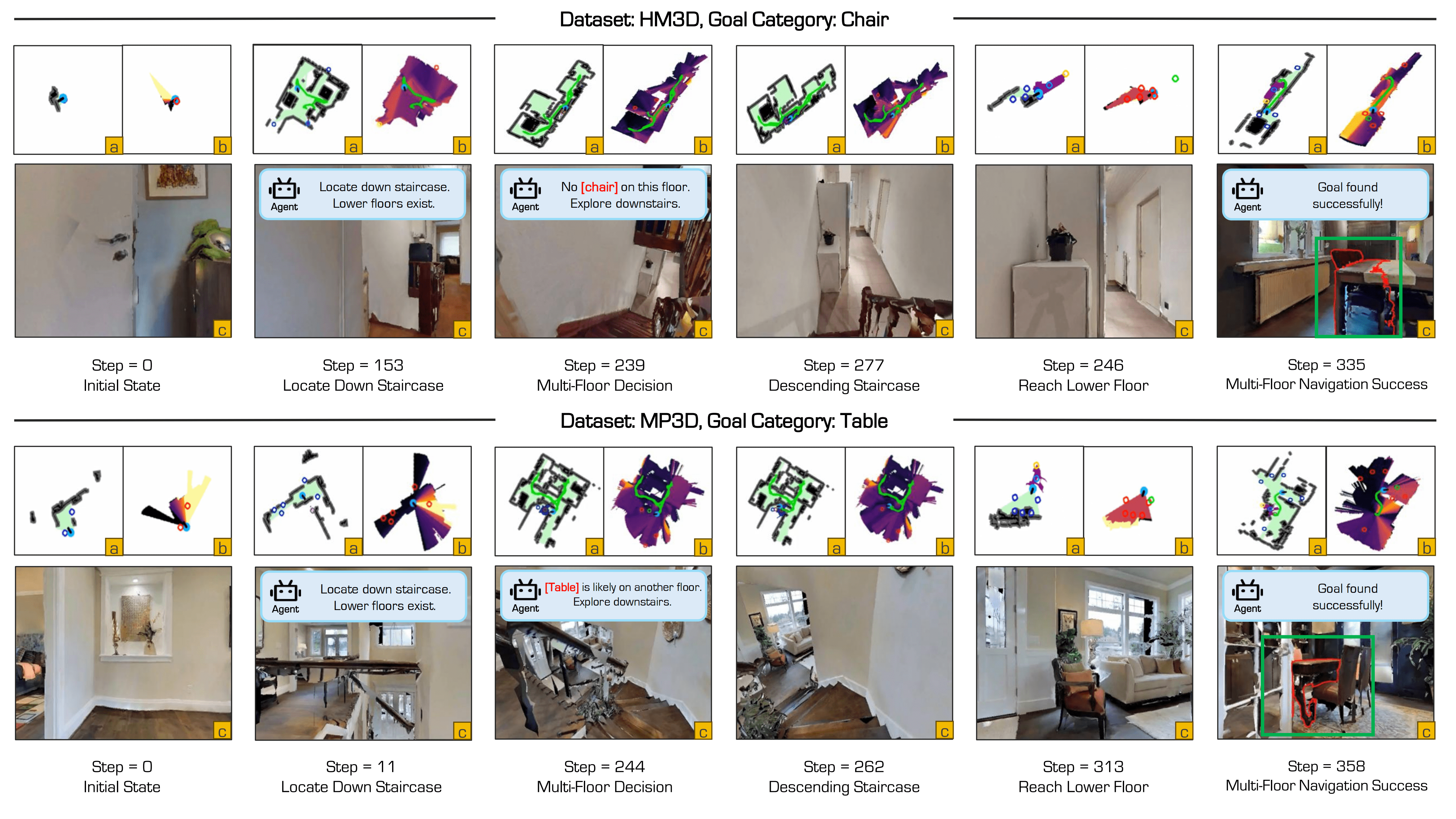
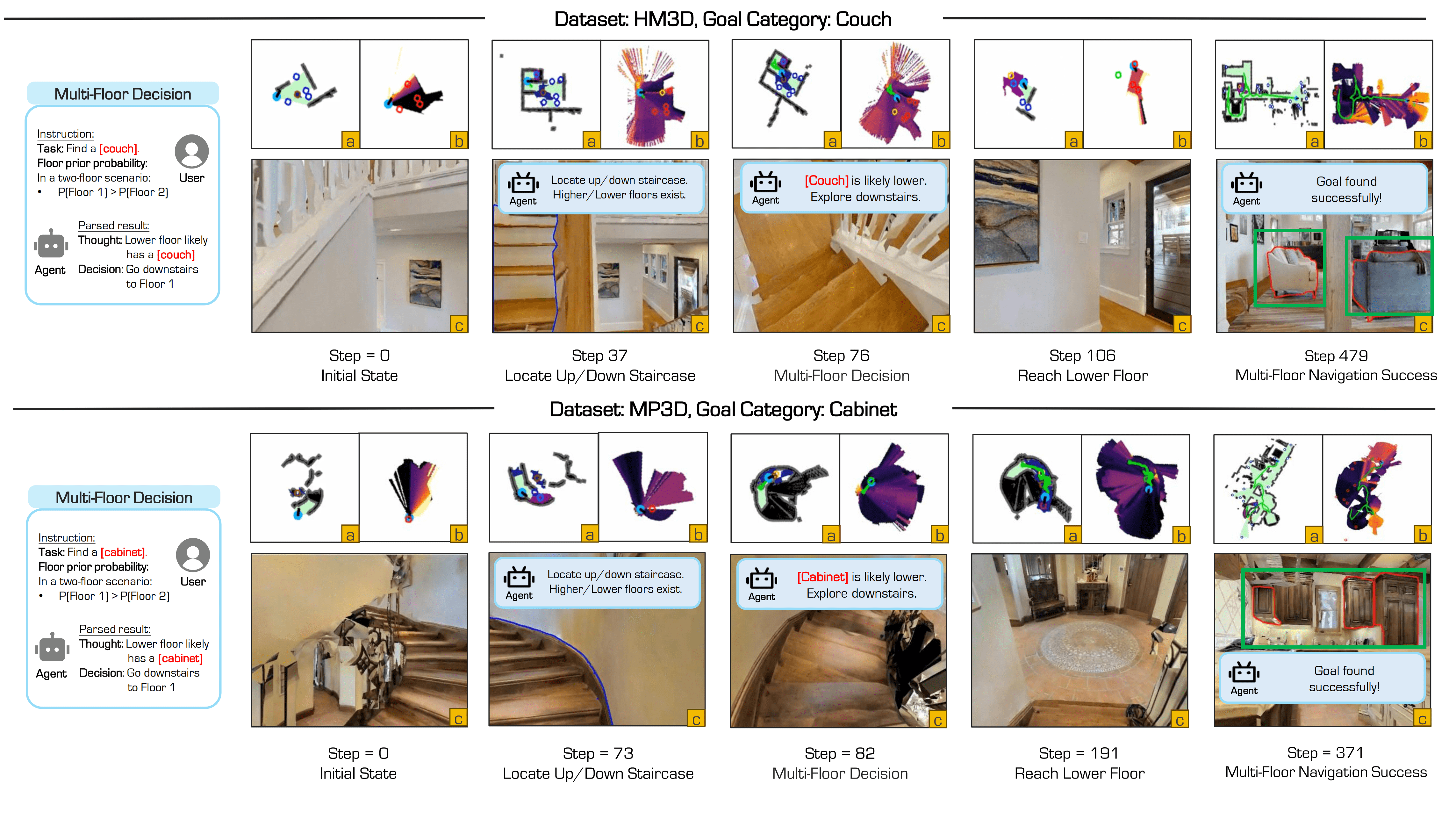
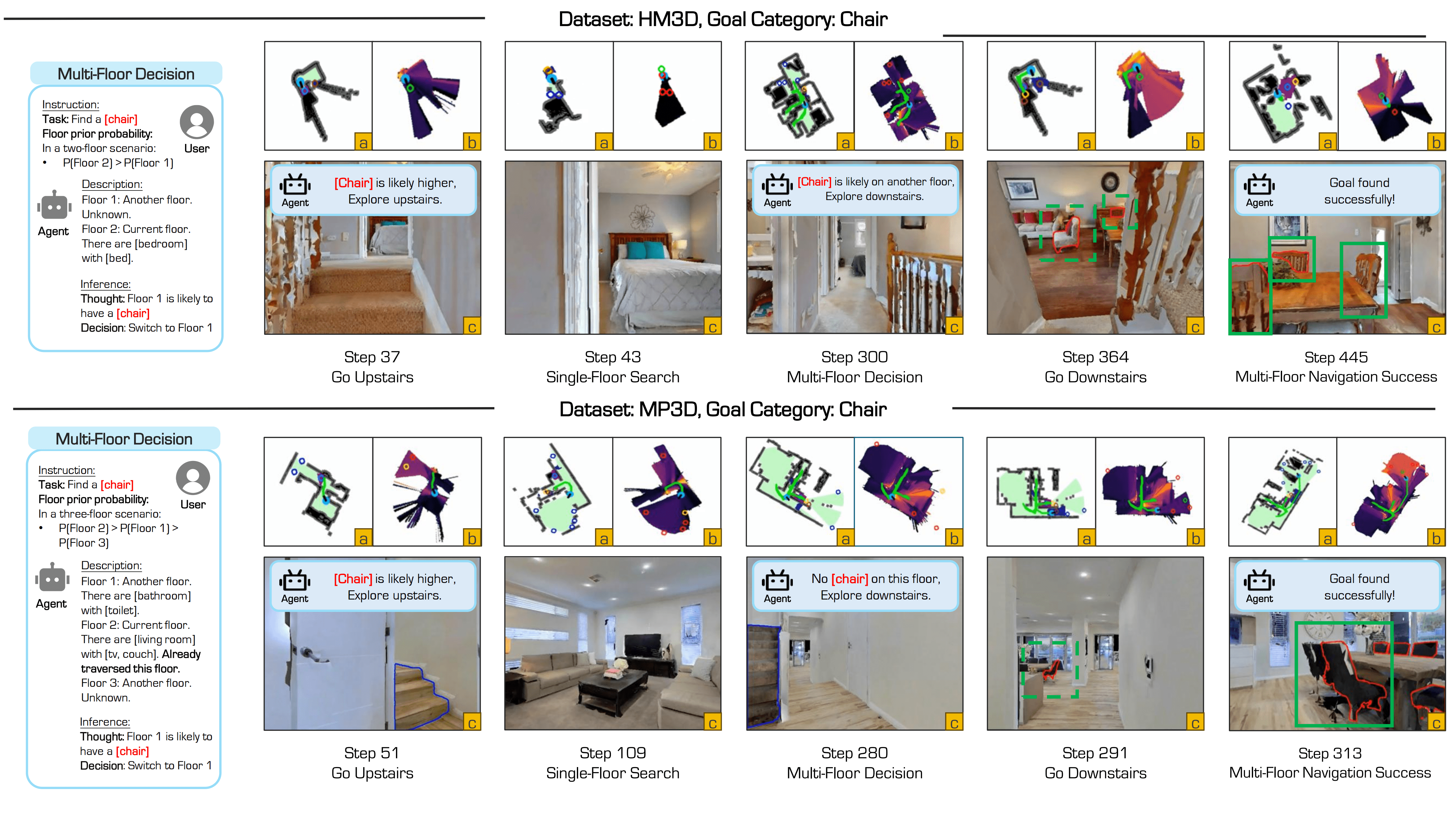
Multi-floor and single-floor navigation with open-vocabulary target objects.
Object-Goal Navigation (OGN) remains challenging in real-world, multi-floor environments and under open-vocabulary object descriptions. We observe that most episodes in widely used benchmarks such as HM3D and MP3D involve multi-floor buildings, with many requiring explicit floor transitions. However, existing methods are often limited to single-floor settings or predefined object categories. To address these limitations, we tackle two key challenges: (1) efficient cross-level planning and (2) zero-shot object-goal navigation (ZS-OGN), where agents must interpret novel object descriptions without prior exposure. We propose ASCENT, a framework that combines a Multi-Floor Spatial Abstraction module for hierarchical semantic mapping and a Coarse-to-Fine Frontier Reasoning module leveraging Large Language Models (LLMs) for context-aware exploration, without requiring additional training on new object semantics or locomotion data. Our method outperforms state-of-the-art ZS-OGN approaches on HM3D and MP3D benchmarks while enabling efficient multi-floor navigation. We further validate its practicality through real-world deployment on a quadruped robot, achieving successful object exploration across unseen floors.
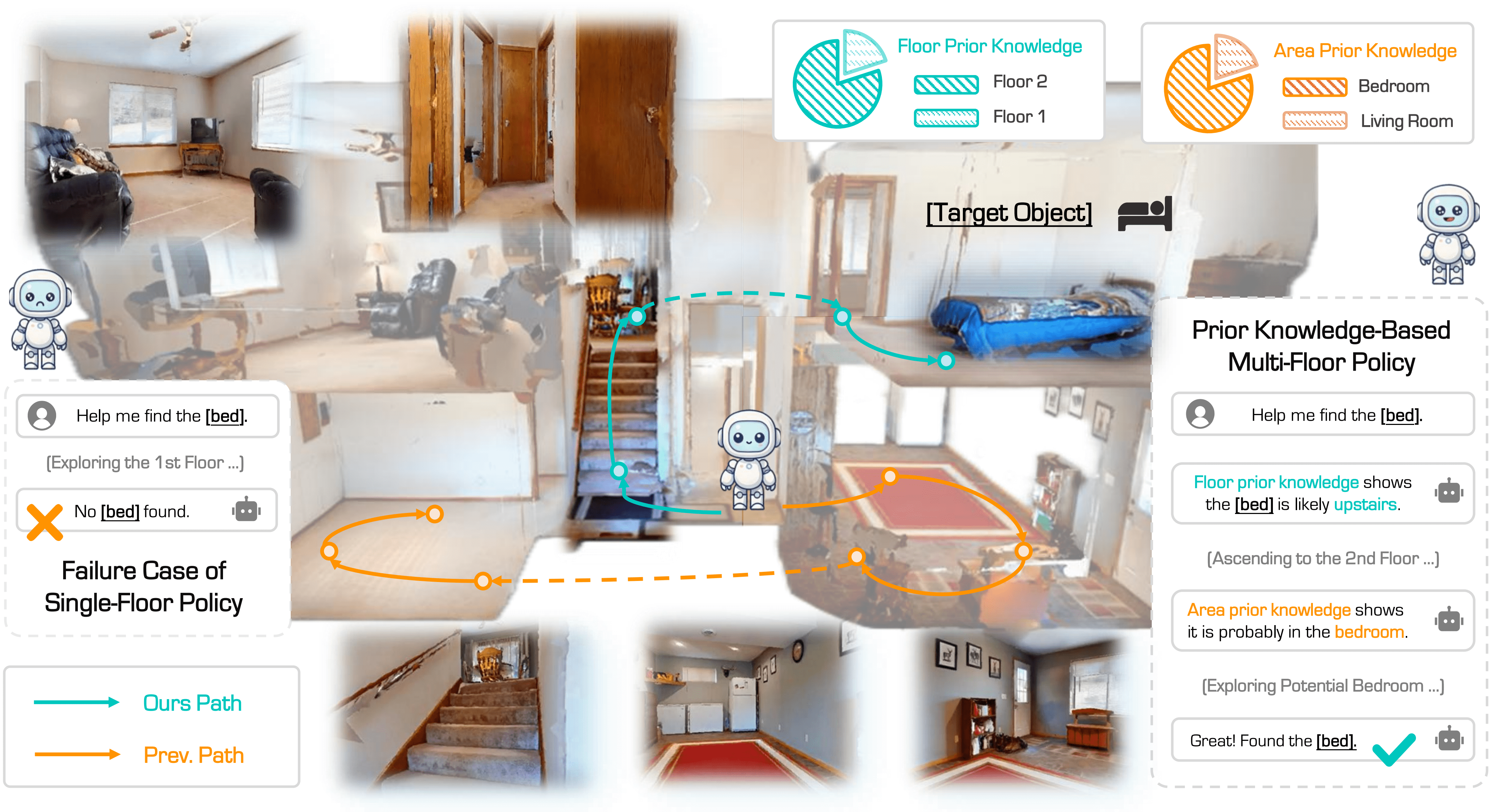
Fig: Motivation & Objective. Our method enables robotic navigation in unexplored multi-floor environments under a zero-shot object-goal setting, leveraging prior knowledge and coarse-to-fine reasoning to prioritize likely target locations. Unlike previous approaches that struggle with floor-aware planning, our method efficiently handles cross-level transitions and successfully locates objects across floors. This demonstrates a meaningful step forward in the zero-shot object-goal navigation field.
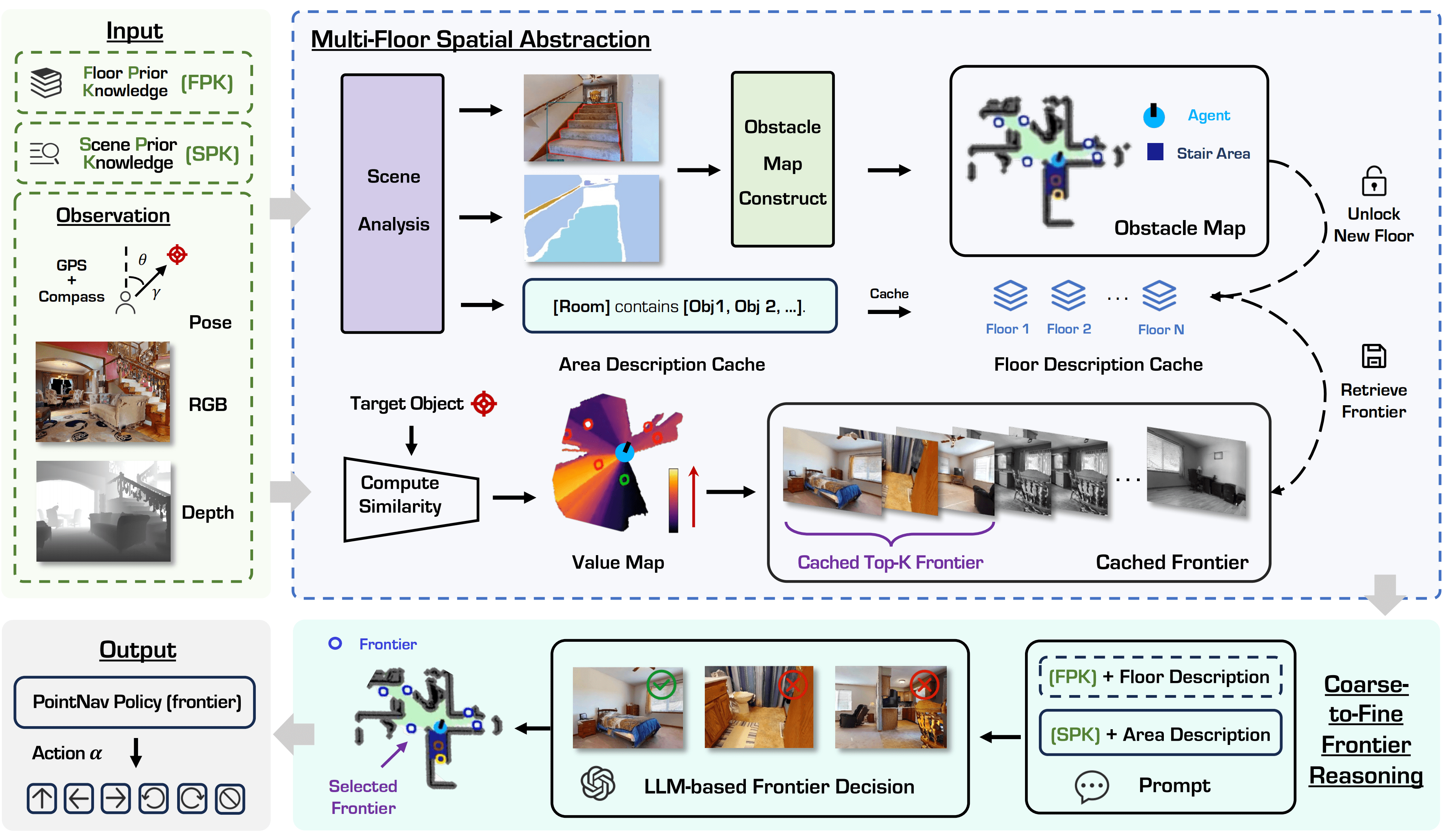
Fig: Overview of the ASCENT framework. The system takes RGB-D and GPS+Compass inputs (top-left), and uses a pretrained navigation policy (bottom-left) to output actions at each timestep. The Multi-Floor Spatial Abstraction module (top-right) builds single-floor BEV maps and models inter-floor connectivity, enabling cross-level navigation. The Coarse-to-Fine Frontier Reasoning module (bottom-right) selects top-k frontiers based on image-text matching scores and uses an LLM for contextual reasoning across floors, achieving efficient zero-shot, floor-aware object navigation.
HM3D and MP3D datasets. Metrics: SR (Success Rate) / SPL (Success weighted by Path Length).
| Setting | Method | Venue | Vision | Language | HM3D SR |
HM3D SPL |
MP3D SR |
MP3D SPL |
|---|---|---|---|---|---|---|---|---|
| Setting: Close-Set | ||||||||
| Single-Floor | SemExp | NeurIPS'20 | - | - | 37.9 | 18.8 | 36.0 | 14.4 |
| Aux | ICCV'21 | - | - | - | - | 30.3 | 10.8 | |
| PONI | CVPR'22 | - | - | - | - | 31.8 | 12.1 | |
| Habitat-Web | CVPR'22 | - | - | 41.5 | 16.0 | 35.4 | 10.2 | |
| RIM | IROS'23 | - | - | 57.8 | 27.2 | 50.3 | 17.0 | |
| Multi-Floor | PIRLNav | CVPR'23 | - | - | 64.1 | 27.1 | - | - |
| XGX | ICRA'24 | - | - | 72.9 | 35.7 | - | - | |
| Setting: Open-Set | ||||||||
| Single-Floor | ZSON | NeurIPS'22 | CLIP | - | 25.5 | 12.6 | 15.3 | 4.8 |
| L3MVN | IROS'23 | - |  GPT-2 GPT-2 | 50.4 | 23.1 | 34.9 | 14.5 | |
| SemUtil | RSS'23 | - | BERT | 54.0 | 24.9 | - | - | |
| CoW | CVPR'23 | CLIP | - | 32.0 | 18.1 | - | - | |
| ESC | ICML'23 | - | GPT-3.5 | 39.2 | 22.3 | 28.7 | 14.2 | |
| PSL | ECCV'24 | CLIP | - | 42.4 | 19.2 | - | - | |
| VoroNav | ICML'24 | BLIP | GPT-3.5 | 42.0 | 26.0 | - | - | |
| PixNav | ICRA'24 | LLaMA-Adapter | GPT-4 | 37.9 | 20.5 | - | - | |
| Trihelper | IROS'24 |  Qwen-VLChat-Int4 Qwen-VLChat-Int4 | GPT-2 | 56.5 | 25.3 | - | - | |
| VLFM | ICRA'24 | BLIP-2 | - | 52.5 | 30.4 | 36.4 | 17.5 | |
| GAMap | NeurIPS'24 | CLIP | GPT-4V | 53.1 | 26.0 | - | - | |
| SG-Nav | NeurIPS'24 | LLaVA | GPT-4 | 54.0 | 24.9 | 40.2 | 16.0 | |
| InstructNav | CoRL'24 | - | GPT-4V | 58.0 | 20.9 | - | - | |
| UniGoal | CVPR'25 | LLaVA | LLaMA-2 | 54.0 | 24.9 | 41.0 | 16.4 | |
| Multi-Floor | MFNP | ICRA'25 | Qwen-VLChat | Qwen2-7B | 58.3 | 26.7 | 41.1 | 15.4 |
| Ours | – | BLIP-2 | Qwen2.5-7B |
65.4 | 33.5 | 44.5 | 15.5 | |
Tab: Quantitative Results on the OGN Task. This table presents quantitative comparisons of the Object-Goal Navigation task on the HM3D and MP3D datasets. It contrasts supervised and zero-shot methods across the metrics of Success Rate (SR) and Success Weighted by Path Length (SPL), highlighting the state-of-the-art performance of our approach in open-vocabulary and multi-floor navigation scenarios.